第7回: WordPress を「Web アプリ」として組む — Custom Post Type と Role 設計の臨界点

実務者向けサマリー:Custom Post Type設計の判断順
- Custom Post Type設計は、画面要件より先に「検索条件」「権限境界」「集計頻度」を確認する。
- Taxonomyは分類・一覧・絞り込みに使い、状態管理や権限制御を背負わせない。
- Metaが増えたら、検索頻度・並び替え・JOIN回数を見てCustom Table化の臨界点を決める。
- RoleとCapabilityは「誰が何を見られるか」ではなく「誰がどの操作を実行できるか」で分ける。
- REST APIやヘッドレス化は最後の出口であり、データモデルの曖昧さを解決する手段ではない。
実装前に register_post_type() の公式ドキュメント とCapabilityの分離を照合し、3年後も保守できる境界を先に引くのがこの回の結論です。
WordPress は 20 年以上のあいだに、ブログツールから「あらゆるコンテンツを乗せる箱」へと変質してきました。
EC、会員制、LMS、求人、不動産、医療予約、社内ナレッジ。実務の現場では、WordPress に Web アプリ的な機能要件が次々と降り注ぎます。
そしてその多くは、初期は素直に動きます。問題は、データが増え、ロールが分岐し、関係が複雑化してきた時に表面化します。
第7回は、WordPress を「Web アプリの実行基盤」として扱うときの設計判断についての話です。
Custom Post Type、Taxonomy、Meta、Role、Capability、Custom Table、REST、ヘッドレス。これらの選択肢のなかで「いつ何を選ぶか」「どこで臨界点を迎えるか」を、フィールドで蓄積した判断軸として整理します。
前回までは 第6回: フォレンジック で侵入後の制御回復を扱い、第4回では ヘッドレス WordPress の設計判断 に触れました。第7回はその延長線上で、「壊れない設計」の土台になるデータモデルの選び方を扱います。
WordPress を Web アプリとして組む時、最大の敵は「便利すぎるデフォルト」です。

CPT を 1 つ追加するだけなら誰でもできます。でも、その判断が 3 年後の運用コストを決めます。第7回は「最初の register_post_type をどう書くか」から始めます。
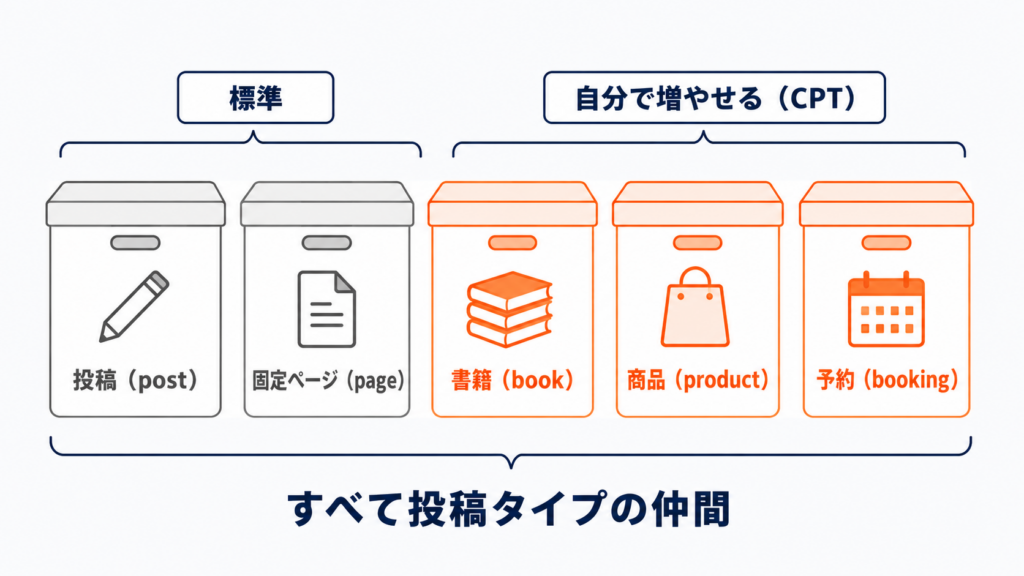
WordPress の「すべてを post で扱う」哲学とその臨界点
WordPress のデータモデルは、驚くほど少ない種類のテーブルで成り立っています。
wp_posts: 記事、固定ページ、添付ファイル、リビジョン、メニュー項目、CPT すべてを保持wp_postmeta: 投稿に紐づくキー / 値ペアwp_users/wp_usermeta: ユーザーとそのメタwp_terms/wp_term_taxonomy/wp_term_relationships: 分類体系wp_options: サイト全体設定とキャッシュ置き場
テーブル数が少ないのは弱さではなく、柔軟性と汎用性のトレードオフです。posts に何でも詰められるからこそ、CPT という発明で「商品」も「コース」も「予約枠」も同じテーブルに乗ります。
しかしこの哲学は、データ量と関係性の複雑度が一定のしきい値を越えると静かに崩壊します。
件数で見る臨界点の目安
ハードウェア、MySQL バージョン、インデックス設計、object cache の有無、テーマやプラグインの hook 密度によって変動しますが、フィールドで観測してきた目安はおおむね次のとおりです。
| 投稿件数 | 観測される挙動 | 対応の難易度 |
|---|---|---|
| 〜1,000 | 標準機能だけで快適に動く | 低 |
| 1,000〜10,000 | 管理画面の一覧、メタクエリで体感が落ち始める | 中 |
| 10,000〜100,000 | wp_postmeta のサイズ問題、autoload 肥大化が顕在化 | 高 |
| 100,000〜 | 投稿一覧の総件数取得クエリが支配的、Custom Table 化を検討 | 非常に高い |
ここで強調したいのは数字そのものではなく「破綻の出方」です。1 万件付近で困るのは件数の絶対値ではなく、「メタで絞り込む」「複数 taxonomy を AND する」「並び順をメタにする」といった操作の組み合わせです。
EC / 会員 / LMS データを WP に乗せる時の判断
「全部 post で表現できる」ことと「全部 post で表現すべき」は別問題です。次の表は、フィールドでの粗い目安です。
| 対象データ | post で扱う | Custom Table 推奨 |
|---|---|---|
| 商品マスタ(数千件) | WooCommerce は post 派生で実用上問題なし | 件数が 10 万を超え、属性検索が重い場合 |
| 受注履歴 | HPOS 以前はメタ依存で重い | WooCommerce HPOS が事実上の標準 |
| 会員プロフィール | users + usermeta で十分 | サブスクや与信履歴を持つなら別テーブル |
| 学習進捗 | ユーザー × コース × レッスンの 3 関係。post で持つと崩れやすい | ほぼ必須 |
| メッセージング / 通知 | 投稿として扱うと膨張する | 別テーブル + キュー |
判断軸(暫定)
- 1 レコードを「投稿として一覧 / 詳細表示する」需要があるか
- メタ検索が支配的になるか(10 個以上のフィルタが交わるか)
- 書き込み頻度がブログ並みか、トランザクション系か
- 他システムからの参照が必要か(API 設計の自由度)
この章のメッセージはひとつです。「WordPress は post に何でも乗せられるが、乗せた瞬間にデータベースの設計者から関数の利用者へと役割が変わる」。乗せた結果として失う自由度を、最初に見積もる必要があります。
ここで補足しておきたいのが、posts テーブルが「投稿」だけのものではないという事実です。
添付ファイル(attachment)、リビジョン、自動保存、ナビゲーションメニューの項目、Gutenberg のリユーザブルブロック(wp_block)、サイトエディタのテンプレート(wp_template)まで、すべて posts テーブルに同居しています。
そのため、件数のカウントには「実投稿だけでなく付随レコード」が混じります。
実務でデータ量を見積もる時は、wp_posts の総レコード数ではなく、post_type 別に GROUP BY したカウントを基準にします。リビジョンを含めて 100 万行を超えるサイトでも、実投稿は 1 万件以下というケースは珍しくありません。
重いのは「実投稿の数」ではなく「クエリプランナがスキャンする範囲」なのです。
運用上、よく問題になるのは autoload 領域の肥大化 です。wp_options の autoload=’yes’ なレコードはリクエストごとにすべてロードされます。
プラグインが乱雑に option を書き込むと、ここが数 MB を超え、ロード時間に直接効きます。
autoload 健全性チェック
SELECT option_name, LENGTH(option_value) AS bytes
FROM wp_options
WHERE autoload = 'yes'
ORDER BY LENGTH(option_value) DESC
LIMIT 20;この出力で MB 単位の option が並ぶようなら、まずそこを切ります。CPT を増やす前に、土台を整えるフェーズです。
もう一点、wp_postmeta は「投稿数 × 平均メタ数」で増えます。1 投稿あたり 20 個のメタを持つ CPT を 5 万件運用すると、postmeta は 100 万行を超えます。
インデックスが効かない検索が走った時の挙動を想像すると、最初の設計で「どのメタは検索する / どれは付帯情報か」を切り分けておく価値が分かります。
Custom Post Type (CPT) を真剣に設計する
register_post_type は手軽です。手軽すぎるがゆえに、ほとんどの現場では引数の意味を吟味せずにデフォルトで通します。これが数年後の運用負債の発生源になります。
<?php
add_action( 'init', function () {
register_post_type( 'course', [
'labels' => [
'name' => 'コース',
'singular_name' => 'コース',
],
'public' => true,
'publicly_queryable' => true,
'show_ui' => true,
'show_in_menu' => true,
'show_in_rest' => true,
'has_archive' => 'courses',
'rewrite' => [
'slug' => 'courses',
'with_front' => false,
],
'supports' => [ 'title', 'editor', 'thumbnail', 'excerpt', 'author' ],
'capability_type' => [ 'course', 'courses' ],
'map_meta_cap' => true,
'menu_position' => 20,
'menu_icon' => 'dashicons-welcome-learn-more',
] );
}, 0 );
public / publicly_queryable / show_ui / show_in_menu / show_in_rest
これらは別々のスイッチです。「とりあえず true」で進めると、本来は公開すべきでない投稿型まで REST に露出します。
public: 他の引数のデフォルトをまとめて切り替えるマスタースイッチpublicly_queryable: フロントエンドのクエリで取得可能かshow_ui: 管理画面に表示するかshow_in_menu: 管理画面のメニュー位置(親メニューにぶら下げる場合は文字列)show_in_rest: REST API に出すか。Gutenberg の編集にも影響exclude_from_search: 標準検索結果からの除外
特に show_in_rest = true はブロックエディタで編集する CPT では前提になりますが、「内部運用専用 CPT」では false のままが安全です。意図せず REST 経由で列挙できる事態を避けます。
supports は最小から積み上げる
supports をデフォルト(title と editor)のまま放置すると、後から「リビジョン履歴がない」「カスタムフィールドが UI から触れない」と気づきます。最初に意図的に列挙したほうが安全です。
title/editor/excerpt/thumbnailauthor: 投稿の所有者を明示。会員制の中核revisions: 教材コンテンツでは保険として有効化page-attributes: 並び順 / 親子関係を扱う場合custom-fields: 旧来のメタ UI が必要な場合のみ
capability_type の重要性
ありがちな落とし穴
capability_type を ‘post’ のままで CPT を作ると、「投稿の編集権限を持つ全員が、その CPT も編集できる」状態になります。会員制サイトで講師ロールを切り出したい時、ここで詰みます。
capability_type を配列で渡し、map_meta_cap を true にすると、edit_course / edit_courses / publish_courses といったきめ細かい権限が自動生成されます。これは H2-7 のロール設計と直結します。
rewrite と URL 設計
rewrite は URL の見た目だけでなく、サイトマップ、内部リンク、リダイレクト設計、SEO すべてに影響します。
slug: アーカイブ URL のスラッグwith_front: パーマリンクの「/blog/」プレフィックスを継承するかfeeds: フィード生成の有無pages: ページネーション URL の生成
後から rewrite を変えると、外部からの被リンク・検索流入・内部リンク・キャッシュをすべて再構築する羽目になります。多くの場合、最初の決定がそのまま 5 年残ります。
CPT を後から変えるコスト
CPT のスラッグ(投稿型名)を変えると、wp_posts.post_type の値が古いまま残ります。手動で UPDATE する必要があります。例として、product から service に切り替える場合のおおまかな手順は次のとおりです。
-- 1. CPT 名の置換(ステージで実行 → 検証 → 本番)
UPDATE wp_posts
SET post_type = 'service'
WHERE post_type = 'product';
-- 2. URL の整合性(rewrite 変更を伴う場合)
-- カスタムリライトは flush_rewrite_rules() を必ず実行する
-- 3. 関連 taxonomy の再登録チェック
SELECT taxonomy, COUNT(*)
FROM wp_term_taxonomy
GROUP BY taxonomy;
CPT 名は「データの本籍地」みたいなものです。気軽に変えると、各種プラグインのメタや外部システムの参照まで全部洗い直す必要が出てきます。命名は熟考の対象です。
CPT 設計でもう一つ見落とされやすいのが「query_var」です。デフォルトでは true で、URL クエリ文字列から ?course=xxx といった呼び出しが可能になります。
意図しない方法で投稿を引かれたくない CPT は、query_var を false にしておくと安全です。
また「menu_position」を意識せずに登録すると、管理画面の左メニューが乱雑になります。投稿型が増えるほど影響が大きく、運用担当者の作業効率に直結します。
20(コメントの下)、25(メディアの下)、80(設定の上)など、整理した数値を割り当てます。
rest_base と rest_controller_class は、REST 経由でこの CPT がどう振る舞うかを決めます。
標準の WP_REST_Posts_Controller では足りない場合、独自コントローラを差し込んでスキーマと権限を厳密化します。これは API 仕様が外部に公開される現場で重要です。
- CPT 名(slug)は 20 文字以内、命名規則に従う。プレフィックスをつける(例: wn_course)
- ラベルは singular_name / name 以外も網羅する(add_new_item / search_items 等)
- taxonomy の関連付けは register_post_type の引数ではなく register_taxonomy で行う
- 後から supports を増やすことは可能だが、減らす時はデータが残るので注意
CPT のラベルを後から大幅に変えると、エクスポートデータや CSV インポートのフォーマットが壊れることがあります。ラベルも「データ仕様」の一部として扱うのが現実的です。
Taxonomy 設計 — フラット vs 階層、いつ使い分けるか
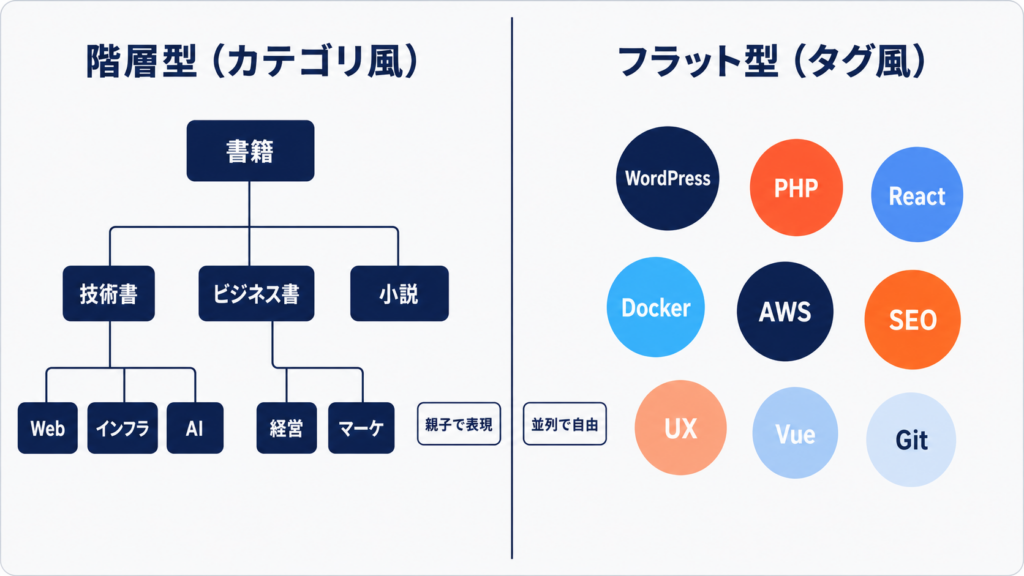
Taxonomy は分類の表現手段です。WordPress では「カテゴリ的(階層あり)」と「タグ的(階層なし)」の 2 系統が register_taxonomy の hierarchical 引数で選択できます。
<?php
register_taxonomy( 'course_subject', 'course', [
'hierarchical' => true, // カテゴリ的
'public' => true,
'show_in_rest' => true,
'show_admin_column' => true,
'rewrite' => [ 'slug' => 'subjects' ],
] );
register_taxonomy( 'course_tag', 'course', [
'hierarchical' => false, // タグ的
'public' => true,
'show_in_rest' => true,
'show_admin_column' => true,
'rewrite' => [ 'slug' => 'course-tags' ],
] );
階層 vs フラットの判断軸
| 観点 | 階層あり(カテゴリ的) | 階層なし(タグ的) |
|---|---|---|
| 想定件数 | 数十〜数百 | 数百〜数千 |
| 管理画面 UI | チェックボックス | オートコンプリート入力 |
| URL 設計 | 親子の入れ子に向く | フラット |
| 並べ替え | 順序を意識した運用 | 並び順は基本扱わない |
| ユーザー入力 | 管理者中心 | 投稿者も追加しがち |
運用上は「管理者しか作らない」「順序がある」「ある程度の数で頭打ち」のものはカテゴリ的に、「自由に増える」「順序を扱わない」「数千スケール」はタグ的にする、というのが目安です。
10,000 ターム超で起きること
タクソノミーのターム数が桁を超えると、いくつかの罠が顔を出します。
- ターム取得関数の N+1(テンプレート内の
get_the_terms()が個別 DB アクセスを生む) - 管理画面の
edit-tags.phpのページネーション・検索が重い - term_relationships のジョインが多段になりプランナが暴れる
- オートコンプリート系プラグインが全件取得を試みてフリーズ
重要
「件数が増えてから対処する」では遅いことが多い領域です。1 万件のタグを保持する可能性のある設計では、最初から検索・絞り込みのアーキテクチャを別系統(Algolia、Meilisearch、ElasticPress)に逃がす想定をしておくと、後悔が少なくなります。
階層的 taxonomy のクエリパフォーマンス問題
hierarchical = true は便利ですが、tax_query で子孫を含めて検索する場合の SQL が膨らみます。WP_Term_Query は子孫を含めるために再帰的にタームを集めるため、深い階層では生成 SQL が長くなります。
階層を 3 階層程度に留め、それ以上の分類は「別 taxonomy として切り出す」か「meta として持つ」のが現実的です。
「タクソノミーで持つ」vs「メタで持つ」の判断
| 性質 | Taxonomy | Meta |
|---|---|---|
| 値が再利用される | ○ | × |
| アーカイブページが必要 | ○ | △ |
| 値の正規化が重要 | ○ | △ |
| 1 投稿に多数値を持つ | ○ | △(複数行) |
| 数値範囲で絞る | × | ○ |
| 並び順を持つ | △ | ○ |
判断軸はシンプルです。「その値で URL を作りたいか」。作りたいなら taxonomy、作りたくないなら meta が出発点です。
taxonomy は CPT に「貼る」ものですが、複数 CPT に同じ taxonomy を貼ることもできます。例えば「業界(industry)」というタクソノミーを「導入事例」と「コラム」両方に貼ると、横断的なアーカイブが作れます。
便利な反面、関連テーマや表示テンプレートを慎重に設計する必要があります。
aliases ではないので、同じスラッグを別 CPT で再利用することはできません。「product_category」と「news_category」のように、CPT 単位で名前を切り分けるのが基本です。
多階層 taxonomy の落とし穴 のもうひとつは「並び順」です。
デフォルトでは name による昇順で、意図的な並びを表現したい場合は term_meta に order を持たせて、get_terms に orderby=’meta_value_num’ を渡します。10 万ターム規模では、ここも性能トラップになります。
判断フロー
- URL に出したい? → taxonomy(はい)/ meta(いいえ)
- 管理者だけが触る? → taxonomy
- 投稿者が自由に増やす? → taxonomy(hierarchical=false)
- 数値で範囲検索したい? → meta
- 1 投稿に複数値を持ち、それぞれが再利用される? → taxonomy
taxonomy の rewrite slug を後から変えると、SEO 影響が出ます。301 リダイレクトと canonical のメンテナンスがセットになるため、リリース前のレビューでスラッグは固めておきます。
Meta データ vs Custom Table — どこで使い分けるか
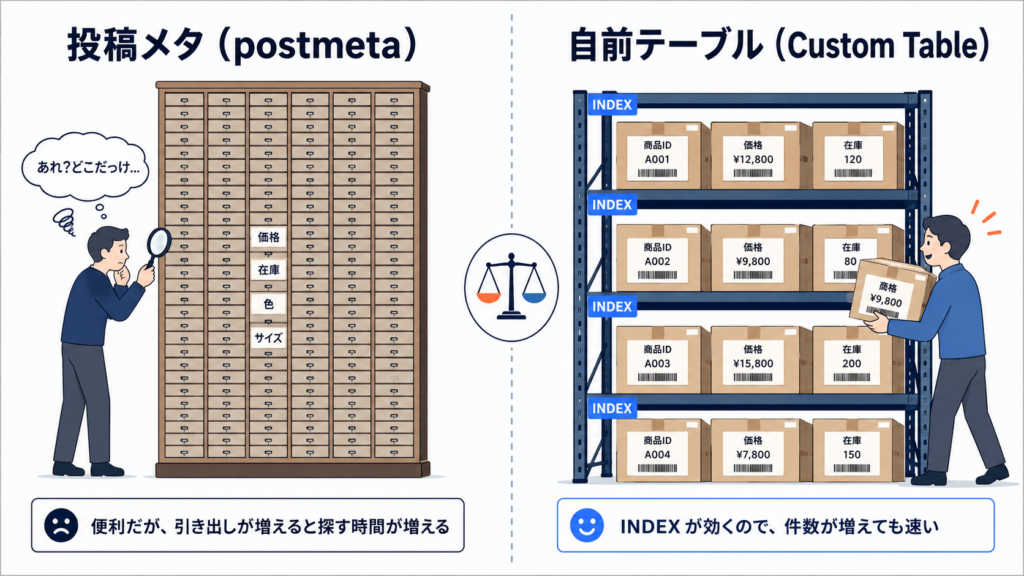
wp_postmeta は柔軟性の象徴です。スキーマレスで、好きなキーに好きな値を入れられます。一方で、その柔軟性は性能のトレードオフです。
postmeta の構造
CREATE TABLE wp_postmeta (
meta_id bigint(20) unsigned NOT NULL AUTO_INCREMENT,
post_id bigint(20) unsigned NOT NULL DEFAULT '0',
meta_key varchar(255) DEFAULT NULL,
meta_value longtext,
PRIMARY KEY (meta_id),
KEY post_id (post_id),
KEY meta_key (meta_key(191))
);
注目すべきは meta_value が longtext である点です。インデックスは meta_key の先頭 191 文字のみ。これが「meta で絞り込む」操作が重くなる根本原因です。
メタクエリの worst case
次のような meta_query は、データ量とともに急速に劣化します。
<?php
$query = new WP_Query( [
'post_type' => 'course',
'meta_query' => [
'relation' => 'AND',
[
'key' => 'price',
'value' => [ 1000, 5000 ],
'type' => 'NUMERIC',
'compare' => 'BETWEEN',
],
[
'key' => 'level',
'value' => 'intermediate',
'compare' => '=',
],
[
'key' => 'language',
'value' => [ 'ja', 'en' ],
'compare' => 'IN',
],
],
] );
- JOIN が 3 回(meta 条件ごとに postmeta が JOIN される)
- meta_value は文字列。BETWEEN は CAST が走り、インデックスが効かない
- 結果セットに加えて総件数取得用のクエリが追加で重い
対症療法と根本治療
- 対症: ‘no_found_rows’ で件数取得クエリを止める / ‘fields’ を ‘ids’ に絞る
- 対症: object cache + transient で結果をキャッシュ
- 対症: 検索用の独立カラムを別テーブルに非正規化
- 根本: meta を Custom Table に分離し、適切なインデックスを張る
Custom Table を切る判断
以下のいずれかが当てはまる時、Custom Table を真剣に検討します。
- 1 投稿あたりの meta レコードが 50 を超える
- meta_query の AND が常時 3 以上で、ヒット件数が数千を超える
- 数値範囲、日時範囲での絞り込みが日常的
- 外部システム(基幹、Stripe、決済代行)が同じデータを参照する
- 履歴系(変更ログ、進捗、ステータス遷移)を持つ
Custom Table の作成例
<?php
/**
* 学習進捗テーブル
* users x courses x lessons の 3 関係を保持する。
*/
add_action( 'plugins_loaded', function () {
global $wpdb;
$table = $wpdb->prefix . 'learning_progress';
$charset = $wpdb->get_charset_collate();
$sql = "CREATE TABLE {$table} (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
user_id BIGINT UNSIGNED NOT NULL,
course_id BIGINT UNSIGNED NOT NULL,
lesson_id BIGINT UNSIGNED NOT NULL,
status VARCHAR(20) NOT NULL DEFAULT 'in_progress',
progress_pct TINYINT UNSIGNED NOT NULL DEFAULT 0,
completed_at DATETIME NULL,
updated_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (id),
UNIQUE KEY uniq_user_lesson (user_id, lesson_id),
KEY user_course (user_id, course_id),
KEY course_status (course_id, status)
) {$charset};";
require_once ABSPATH . 'wp-admin/includes/upgrade.php';
dbDelta( $sql );
} );
$wpdb の作法
<?php
global $wpdb;
// 安全な書き方(prepare で必ずバインド)
$user_id = 123;
$status = 'completed';
$rows = $wpdb->get_results(
$wpdb->prepare(
"SELECT course_id, COUNT(*) AS done
FROM {$wpdb->prefix}learning_progress
WHERE user_id = %d AND status = %s
GROUP BY course_id",
$user_id,
$status
)
);
// 危険な書き方(避ける)
// $rows = $wpdb->get_results( "SELECT ... WHERE user_id = {$_GET['uid']}" );
$wpdb の周辺は WordPress の例外領域です。テンプレートタグや WP_Query では SQL を意識せずに済みますが、Custom Table を扱った瞬間に、SQL インジェクションの責任が開発者に戻ってきます。
既存メタを Custom Table へ移行する戦略
- Step 1: 読み取り API を関数化(直接 get_post_meta を呼ばない層を作る)
- Step 2: 二重書き込み(旧 meta と新 table の両方に書く期間を設ける)
- Step 3: バックフィル(既存 meta を新テーブルに流し込む)
- Step 4: 読み取りを Custom Table に切り替え
- Step 5: 旧 meta の削除(バックアップを取った上で)
段階移行は退屈ですが、退屈な手順を踏まないとデータ事故が起きます。「動いている meta は消さない」が鉄則です。
postmeta の弱点を補う中間策として「serialized meta」と「JSON カラム化」があります。前者は WordPress 標準の挙動で、配列をシリアライズして 1 行に詰めるもの。
後者は postmeta に JSON 文字列を入れ、必要に応じてアプリ層でパースする方式です。
いずれも検索性とトレードオフになります。serialized メタは内部で正しく取り出せても、SQL で WHERE 句に使うのは現実的ではありません。検索したい属性は別カラム(または別テーブル)に正規化する、というのが基本姿勢です。
Custom Table のメリットは性能だけではありません。「スキーマが見える」「他システムから直接 SELECT できる」「外部キー(疑似的にでも)で関係を明示できる」といった、ソフトウェア工学的な健全性が手に入ります。
- MySQL の InnoDB ロック粒度を気にして、書き込み頻度の高いテーブルは PRIMARY KEY を昇順 ID にする
- 更新日時カラムには ON UPDATE CURRENT_TIMESTAMP を入れ、リプリケーション側で差分検出を可能にする
- 削除は論理削除(deleted_at カラム)にしておくと、復旧が容易
- BIGINT を使う(INT は 21 億で枯渇)
$wpdb はプリペアドステートメントを提供しますが、IN 句のバインディングが標準では弱いです。複数値を IN で渡す場合、安全に書くには次のような書式が定石です。
<?php
$ids = [1, 2, 3, 4, 5];
$placeholders = implode( ',', array_fill( 0, count( $ids ), '%d' ) );
$sql = $wpdb->prepare("SELECT * FROM {$wpdb->prefix}learning_progress WHERE user_id IN ({$placeholders})",
$ids
);
$rows = $wpdb->get_results( $sql );地味ですが、こうした作法を徹底することが、後の保守性と安全性を支えます。
ACF / Pods / SCF / Meta Box の本当の使い分け
カスタムフィールド系プラグインは、表面的には似た機能を提供します。しかしその思想と、大規模になった時の挙動はかなり違います。
| プラグイン | 強み | 弱み / 注意点 |
|---|---|---|
| ACF Pro | UI が成熟。フィールドグループの可視化 | Pro ライセンス / 大量フィールドで JSON 同期が重い |
| Pods | CPT + Custom Table を統合管理 | 学習コスト高。Pods 流の構造に縛られる |
| SCF | 軽量で素直 | 高度なリレーション機能は不足 |
| Meta Box | コードベースで管理しやすい | GUI が ACF より素朴 |
ACF Pro: フィールドグループ + UI
ACF Pro は管理者と開発者の橋渡しが上手です。フィールドを GUI で定義し、JSON 同期で Git に乗せられます。
- フィールドが 100 を超えると JSON ファイルが肥大化
- Flexible Content / Repeater はメタを「複数行」として持つため、検索性は良くない
- ACF Blocks は便利だが、ブロックの再利用性は限定的
Pods: CPT + Custom Table 統合
Pods は唯一、Custom Table への書き込みを GUI で扱えるプラグインです。スキーマ的に「正規化したい」ニーズと相性が良い反面、Pods のロックインが発生します。
SCF (Smart Custom Fields): 軽量
ACF の代替として注目される SCF は、構造がシンプルで、必要十分なフィールドタイプを揃えています。リレーションやコンテクスト的フィールド設定は ACF Pro に劣ります。
Meta Box: コードベース重視
Meta Box はフィールド定義を PHP コードで書くスタイルが基本です。Git 管理と相性が良く、エンジニア主導の現場で選ばれます。
大規模サイトでの選定ガイドライン
- 管理者がフィールドを編集する:ACF Pro / Pods
- エンジニアが GUI を絞り込む:Meta Box / SCF
- Custom Table が必要:Pods(または自前実装)
- プラグイン依存を抑えたい:SCF + 必要に応じて Custom Table 自前
- ヘッドレス(REST / GraphQL):ACF + WPGraphQL for ACF / Meta Box
「ACF があれば万事 OK」は半分正解で半分罠です。フィールドが千件超える運用では、JSON 同期だけで日々のデプロイが重くなります。最初から「捨てやすい設計」を意識します。
プラグイン選定で見落とされがちなのが「フィールド定義のポータビリティ」です。ACF Pro は JSON 同期で Git に乗せられますが、エクスポート / インポートのバージョン互換は完全ではありません。
プラグインのメジャー更新時に、JSON フォーマットが微妙に変わることがあります。
「フィールド定義はコード」 と割り切る現場では、ACF も acf_add_local_field_group() を使ってコードベースで定義します。これなら GUI で誤って編集された場合にも、コードが SSoT として残ります。
- 管理者が GUI で編集する権限を持つかどうか、最初に決める
- 本番サイトの GUI から保存できないようにする選択肢(disable acf-json sync)
- ステージング → 本番の同期手順を文書化する
- プラグインのライセンス更新切れに備える(ACF Pro は更新切れで自動更新停止)
プラグイン依存の量を見積もる
カスタムフィールドプラグインは「外せない」ことが多いものです。一度 ACF Pro で 200 フィールドを定義すると、別プラグインに移行するコストは数日〜数週間。
最初の選択が長く効くため、ライセンス費用だけでなく、5 年後の互換性まで含めて評価します。
WP_Query の臨界点とパフォーマンス設計
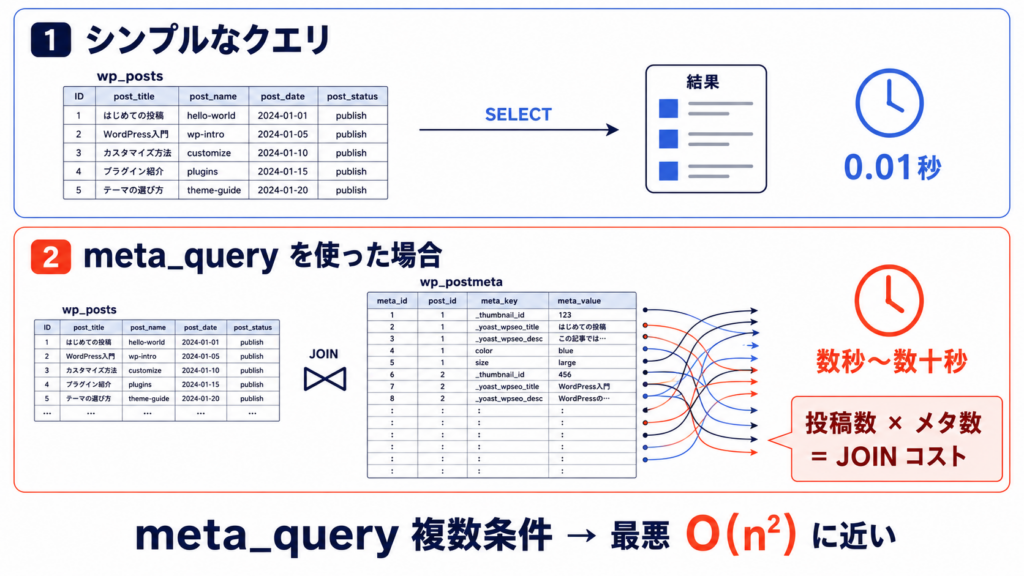
WP_Query は WordPress の中核 API です。柔軟である一方、引数の一つで SQL が数十倍重くなることもあります。
meta_query の性能トラップ
meta_query は便利ですが、ヒット件数が 1,000 を超えた頃から劣化が顕在化します。原因は前章で述べた postmeta テーブルのインデックス構造です。
tax_query の罠
<?php
$query = new WP_Query( [
'post_type' => 'course',
'tax_query' => [
'relation' => 'AND',
[
'taxonomy' => 'course_subject',
'field' => 'slug',
'terms' => [ 'web', 'design' ],
'include_children' => true,
],
[
'taxonomy' => 'course_tag',
'field' => 'slug',
'terms' => [ 'beginner' ],
],
],
] );
include_children = true は子孫まで含めるためにタームを再帰的に拡張します。階層が深いほど IN 句が膨張します。
軽量化の常套手段
'no_found_rows' => true: ページネーションが不要なら有効。総件数を取得する追加クエリを止められる'update_post_meta_cache' => false: メタを使わない一覧で必須'update_post_term_cache' => false: 同様にターム不要時'fields' => 'ids': ID だけ取得して個別に必要な時のみ詳細を引く'posts_per_page' => -1は避ける(件数上限を設ける)
<?php
$ids = get_posts( [
'post_type' => 'course',
'posts_per_page' => 100,
'fields' => 'ids',
'no_found_rows' => true,
'update_post_meta_cache' => false,
'update_post_term_cache' => false,
'orderby' => 'date',
'order' => 'DESC',
] );
// 必要な行だけ詳細取得
foreach ( $ids as $id ) {
$title = get_the_title( $id );
// ...
}
transient + object cache の併用
<?php
function wn_get_featured_courses() {
$cache_key = 'wn_featured_courses_v3';
$ids = wp_cache_get( $cache_key, 'wn_courses' );
if ( false === $ids ) {
$ids = get_posts( [
'post_type' => 'course',
'posts_per_page' => 12,
'meta_key' => 'is_featured',
'meta_value' => '1',
'fields' => 'ids',
'no_found_rows' => true,
] );
wp_cache_set( $cache_key, $ids, 'wn_courses', 10 * MINUTE_IN_SECONDS );
}
return $ids;
}
// 該当データが変わるタイミングで invalidate
add_action( 'save_post_course', function ( $post_id ) {
wp_cache_delete( 'wn_featured_courses_v3', 'wn_courses' );
} );
設計原則
「クエリで取らない、ループで動くスナップショットで取る」。アクセスごとに WP_Query を回すのではなく、変更時にスナップショットを作ってキャッシュに置き、表示時はキャッシュをなめるだけにします。
一覧ページの WP_Query は、サイトのアクセス数に応じて指数的に効きます。月 10 万 PV で気にならない処理が、100 万 PV で死にます。スナップショット設計は早い段階で入れます。
WP_Query を語る上で、もう一つ重要なのが「pre_get_posts」フックの活用です。テンプレートで WP_Query を新規に書くより、メインクエリを pre_get_posts で修正するほうがキャッシュやテンプレート階層と整合しやすいケースが多いです。
<?php
add_action( 'pre_get_posts', function ( $query ) {
if ( is_admin() || ! $query->is_main_query() ) {
return;
}
if ( is_post_type_archive( 'course' ) ) {
$query->set( 'posts_per_page', 12 );
$query->set( 'meta_key', 'sort_order' );
$query->set( 'orderby', 'meta_value_num' );
$query->set( 'order', 'ASC' );
}
} );object cache を効かせる前提 の設計は、月数百万 PV 規模で効きます。
Redis / Memcached の object cache がない状態で transient だけに頼ると、transient が wp_options に書かれて autoload を圧迫することがあります。
本番環境では Redis を前提に設計するのが現実解です。
- transient は object cache が無い場合、wp_options に書かれる
- site transient は wp_sitemeta(マルチサイト)または wp_options
- object cache がある場合、transient はキャッシュバックエンドに格納される
- 短命なキャッシュは transient より wp_cache_set のほうが軽い
実装の指針として、「ページのレンダリングに必要なすべての SQL を 50ms 以内に終える」ことを目標にすると、自然と meta_query を減らし、スナップショット設計に向かいます。
ロール + Custom Capability で複雑な権限制御
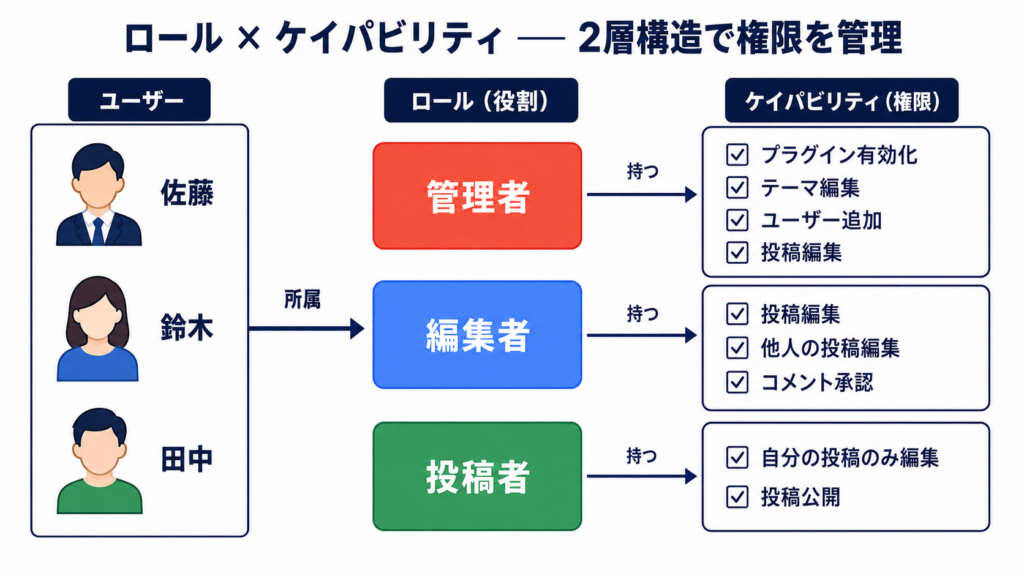
WordPress の標準ロール(administrator / editor / author / contributor / subscriber)は、ブログ運営には十分ですが、会員制や LMS では足りません。
既存ロールの限界
- editor は他人の投稿も編集できる。これは「講師」には強すぎる
- subscriber は閲覧のみ。「無料会員」と「有料会員」を区別できない
- author は自分の投稿は編集できるが、CPT 単位の制限はかけにくい
add_role と add_cap で増やす
<?php
register_activation_hook( __FILE__, function () {
add_role( 'instructor', '講師', [
'read' => true,
'edit_courses' => true,
'edit_published_courses' => true,
'publish_courses' => true,
'delete_courses' => false,
'upload_files' => true,
] );
add_role( 'paid_member', '有料会員', [
'read' => true,
'read_premium' => true,
] );
add_role( 'free_member', '無料会員', [
'read' => true,
] );
} );
register_deactivation_hook( __FILE__, function () {
remove_role( 'instructor' );
remove_role( 'paid_member' );
remove_role( 'free_member' );
} );
注意
add_role と add_cap は DB に書き込まれます。プラグインを停止しただけではロールは消えません。アンインストール時の cleanup を実装しておきます。
map_meta_cap でファイングレイン制御
CPT の capability_type を配列で指定し map_meta_cap = true にすると、edit_post といったメタ capability が edit_course / edit_others_courses といった具体的な capability に展開されます。
<?php
// 講師は自分のコースだけを編集可能、他人のコースは編集不可
add_filter( 'map_meta_cap', function ( $caps, $cap, $user_id, $args ) {
if ( 'edit_course' !== $cap || empty( $args[0] ) ) {
return $caps;
}
$post = get_post( $args[0] );
if ( ! $post ) {
return $caps;
}
if ( (int) $post->post_author === (int) $user_id ) {
$caps = [ 'edit_courses' ];
} else {
$caps = [ 'edit_others_courses' ];
}
return $caps;
}, 10, 4 );
会員制 / LMS の典型シナリオ
| 要件 | 実装の起点 |
|---|---|
| 無料会員と有料会員で読める記事が違う | role + meta + テンプレート判定 |
| 講師は自分のコースだけ編集可能 | map_meta_cap + post_author 判定 |
| メンター(補助講師)は閲覧と添削のみ | 新規 role + コメント関連 capability |
| 管理者でもログを編集不可(監査要件) | edit_logs を誰にも付与しない |
プラグインの比較
| プラグイン | 強み | 向くケース |
|---|---|---|
| Members | シンプル。コードに近い思想 | エンジニア主導の小〜中規模 |
| User Role Editor | 既存ロールを編集する UI が充実 | 既存サイトに後付けで権限整理 |
| Capability Manager Enhanced | capability の一覧性が高い | 監査・棚卸し |
ロール設計は「足し算」ではなく「割り算」で考えると整理しやすいです。標準ロールから余計な capability を引き、必要なものだけ残す。最初に全部足しに行くと、後で「誰が何できるか」が誰にも説明できなくなります。
capability の追加と削除は、データベース(wp_options の wp_user_roles)に直接書き込まれます。プラグインのコードを変えても、すでに DB に書かれたロールは残るため、デプロイの順序を意識する必要があります。
設計のコツは「最小権限の原則」です。新しい role を作ったら、まず capability ゼロから始め、必要なものだけ足します。既存 role を継承して引き算するアプローチは、引き算漏れが事故になりがちです。
- current_user_can( ‘edit_course’, $course_id ) のように、対象 ID を渡せる形で判定する
- 管理画面のリスト表示も capability で絞る(show_in_menu や show_ui だけでは不完全)
- WP_REST_Controller の permission_callback でも同じ capability を再チェックする
- テンプレート側で capability を確認する(テーマで現在のユーザーロールに依存しない)
ロール監査の SQL
SELECT option_value
FROM wp_options
WHERE option_name = 'wp_user_roles';この値はシリアライズされた配列です。phpMyAdmin や WP-CLI で読み出してフォーマットすると、現在の capability マッピングが一覧できます。年に 1 回は棚卸しをおすすめします。
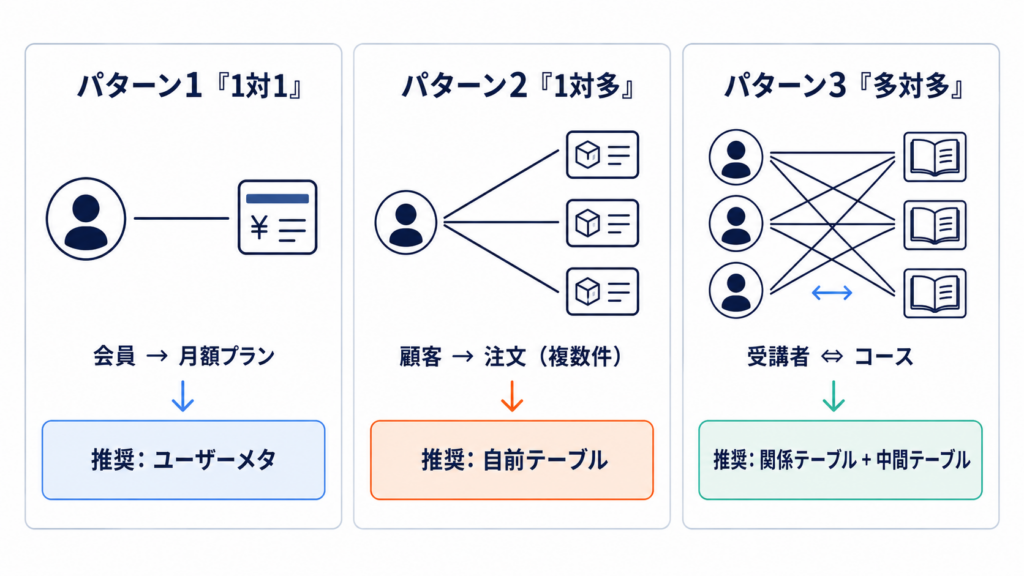
ユーザーとデータの所有関係(会員制 / LMS の中核設計)
会員制サイトや LMS の中核は、突き詰めれば「ユーザー X はコンテンツ Y にアクセス可能か」という関係の表現です。
post_author に依存した設計の限界
WordPress には post_author という古い仕組みがあります。1 つの投稿には 1 人の所有者。この前提は、ブログには適合しますが、次のような要件では破綻します。
- 1 つのコースを複数の講師で共同編集する
- 1 人の受講生が複数のコースを購入し、それぞれに進捗を持つ
- メンターと受講生の N:N 関係
- ロールが時間軸で変わる(無料 → 有料 → 卒業生)
usermeta vs custom relation table
「X さんが Y にアクセスできる」を表現する方法は大別して 3 つあります。
| 手法 | 向くケース | 限界 |
|---|---|---|
| usermeta に許可コースの ID 配列 | 件数が少なく、頻繁に変わらない | 配列が長くなると遅い / 検索不可 |
| postmeta に許可ユーザーの ID 配列 | コース側で誰が見られるか管理する | ユーザーから引く時に重い |
| custom relation table | N:M 関係を本格的に持つ | 実装と運用のコストがかかる |
<?php
/**
* ユーザーとコースの関係を保持する N:M テーブル
*/
add_action( 'plugins_loaded', function () {
global $wpdb;
$table = $wpdb->prefix . 'user_course_access';
$charset = $wpdb->get_charset_collate();
$sql = "CREATE TABLE {$table} (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
user_id BIGINT UNSIGNED NOT NULL,
course_id BIGINT UNSIGNED NOT NULL,
granted_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
expires_at DATETIME NULL,
source VARCHAR(40) NOT NULL DEFAULT 'purchase',
PRIMARY KEY (id),
UNIQUE KEY uniq_user_course (user_id, course_id),
KEY course_id (course_id),
KEY expires_at (expires_at)
) {$charset};";
require_once ABSPATH . 'wp-admin/includes/upgrade.php';
dbDelta( $sql );
} );
function wn_user_can_access_course( $user_id, $course_id ) {
global $wpdb;
$table = $wpdb->prefix . 'user_course_access';
$row = $wpdb->get_row( $wpdb->prepare(
"SELECT id, expires_at FROM {$table}
WHERE user_id = %d AND course_id = %d",
$user_id, $course_id
) );
if ( ! $row ) {
return false;
}
if ( $row->expires_at && strtotime( $row->expires_at ) < time() ) {
return false;
}
return true;
}
LMS でのコース進捗管理
進捗データはトランザクション系の典型です。書き込み頻度が高く、読み出し時はユーザー軸・コース軸両方で集計が必要になります。postmeta では桁が変わると破綻します。
- user_id × lesson_id の複合ユニークキー
- course_id ごとの集計に備えた複合インデックス
- 状態遷移ログを別テーブルに分離(in_progress / completed / abandoned)
- 保存タイミングを debounce(ページ離脱時の bulk update)
EC での顧客と注文の関係
WooCommerce が HPOS(High-Performance Order Storage)を導入したのは、まさにこの「post + meta で注文を持つ」設計の限界に対する公式回答です。HPOS は注文を独立テーブルに置き、postmeta による N+1 を解消します。
実務メモ
既存 WooCommerce サイトが古い場合、HPOS への移行は意外と慎重さが必要です。決済プラグインや拡張プラグインが HPOS 対応していない場合、互換モードでの両走期間が必要になります。
関係テーブルを設計する際、「リレーション以外に何を持たせるか」が論点になります。
granted_at と expires_at だけで足りる場合もあれば、source(購入元)、payment_id(決済 ID)、refunded_at(返金日時)といった監査情報まで含めるケースもあります。
監査要件がある業種では、関係テーブルに変更ログを残す のが基本です。アクセス権が「いつ、どの経路で、誰の操作で付与・剥奪されたか」を 5 年単位で保持できる構造を最初に作っておきます。
- 関係テーブルとは別に events テーブル(変更ログ)を持つ
- INSERT / UPDATE / DELETE のたびに events に 1 行追加する
- events は更新せず append のみ、容量見積もりは別途
- 古い events は別ストレージにアーカイブする運用設計
HPOS(WooCommerce)は、まさにこの「関係を独立テーブルに分離した上で、必要な監査情報を伴って保持する」設計の WordPress 実装です。コミュニティが 10 年かけて辿り着いた解として、汎用性高く参考になります。
<?php
/**
* アクセス権の付与をログに残す
*/
function wn_grant_course_access( $user_id, $course_id, $args = [] ) {
global $wpdb;
$table = $wpdb->prefix . 'user_course_access';
$events = $wpdb->prefix . 'user_course_events';
$wpdb->insert( $table, [
'user_id' => $user_id,
'course_id' => $course_id,
'source' => $args['source'] ?? 'manual',
'expires_at' => $args['expires_at'] ?? null,
], [ '%d', '%d', '%s', '%s' ] );
$wpdb->insert( $events, [
'user_id' => $user_id,
'course_id' => $course_id,
'event' => 'granted',
'source' => $args['source'] ?? 'manual',
'actor_id' => get_current_user_id(),
], [ '%d', '%d', '%s', '%s', '%d' ] );
}この程度の冗長性は、後で「いつ誰がアクセス権を付与したか分からない」という質問が来た時に効きます。サポート対応のコストにも直結します。
WordPress + WooCommerce + LMS の Stack 設計例
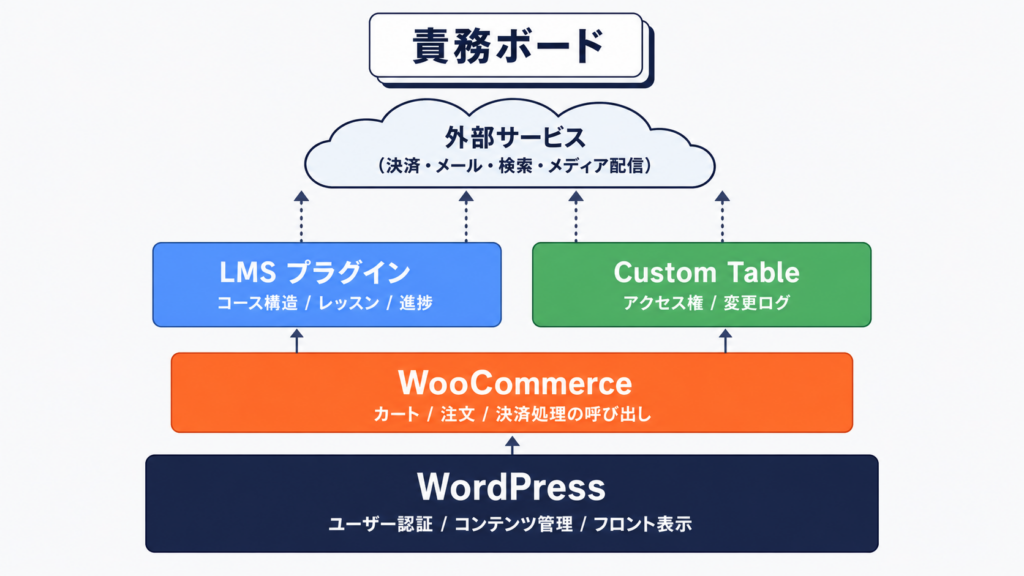
ここでは、よくあるオンライン学習プラットフォームの典型構成を題材に、データフローと整合性の維持を考えます。
典型的な構成
- 販売層: WooCommerce(商品、カート、決済)
- コンテンツ層: LearnDash / Tutor LMS / 自前 CPT(コース、レッスン)
- 会員層: WordPress User + 独自 role + custom relation table
- 外部連携: Stripe(決済), SendGrid(メール), Zoom(ライブ授業)
カートから受講開始までのフロー
<?php
/**
* 注文完了時にコースアクセス権を付与する典型フロー
*/
add_action( 'woocommerce_order_status_completed', function ( $order_id ) {
$order = wc_get_order( $order_id );
if ( ! $order ) {
return;
}
$user_id = $order->get_user_id();
if ( ! $user_id ) {
return; // ゲスト購入時の別フロー
}
foreach ( $order->get_items() as $item ) {
$product_id = $item->get_product_id();
$course_id = (int) get_post_meta( $product_id, '_linked_course_id', true );
if ( ! $course_id ) {
continue;
}
wn_grant_course_access( $user_id, $course_id, [
'source' => 'wc_order:' . $order_id,
'expires_at' => null,
] );
}
}, 20, 1 );
データ整合性の維持
見落としやすい整合性の崩れ方
- 返金処理(refund)で「アクセス権を取り消す」忘れ
- サブスクの自動更新失敗時のグレースピリオド設計
- カート放棄からの復活注文
- 管理画面からの手動ステータス変更
- 外部 webhook の重複配送
単一データソースの原則を WP で守るには
Single Source of Truth(SSoT)は理想ですが、WordPress の世界では「事実上 3 つの SSoT が併存する」状態を受け入れる現実主義が必要です。
| データ | SSoT 候補 | コメント |
|---|---|---|
| 決済情報 | Stripe | WP に同期するが原本は外部 |
| 注文 | WooCommerce(HPOS) | WP 内部に持つ |
| コースアクセス権 | Custom Table | WP 内部だが post とは別系統 |
| メール配信履歴 | SendGrid / Mailgun | 外部 |
「WP がすべての中心」と思い込まないことが、複雑構成での破綻を防ぎます。
WordPress + WooCommerce + LMS の三層構成は、現場では「動いている」状態を維持するだけで一仕事です。新規機能追加の前に、整合性を担保する webhook と reconciliation バッチを設計します。
WordPress + WooCommerce + LMS のスタックで頻出するのが「責務の重複」です。例えば「メール配信」は WooCommerce にもあり、LMS プラグインにもあり、独自テンプレートにもあります。
どこから何が送られているかを把握するだけで、サポート工数が増えます。
メール送信は wp_mail() フックで一本化 し、テンプレートと宛先を中央集権化するのが現実的です。SendGrid や Mailgun に出す場合も、内部からは wp_mail を呼ぶことで、後の差し替えが効きます。
- wp_mail を SMTP プラグイン経由で外部サービスに飛ばす
- メールテンプレートはコード(または ACF)で管理し、プラグインのテンプレートを上書きする
- イベントごとに送信元を統一する(noreply@ ではなく、用途別のアドレス)
- 配信ログを外部側(SendGrid)と内部側(WP)で照合する仕組み
もう一つ重要なのが「webhook の冪等性」です。Stripe からの webhook、SendGrid からのバウンス通知などは、リトライで重複配送されることがあります。event_id で重複チェックを入れる癖をつけます。
responsibility ボード
- WordPress: ユーザー認証、コンテンツ管理、フロント表示
- WooCommerce: カート、注文、決済処理の呼び出し
- LMS: コース構造、レッスン、進捗
- Custom Table: アクセス権、変更ログ
- 外部サービス: 決済、メール、検索、メディア配信
REST API / GraphQL での効率的データ取得
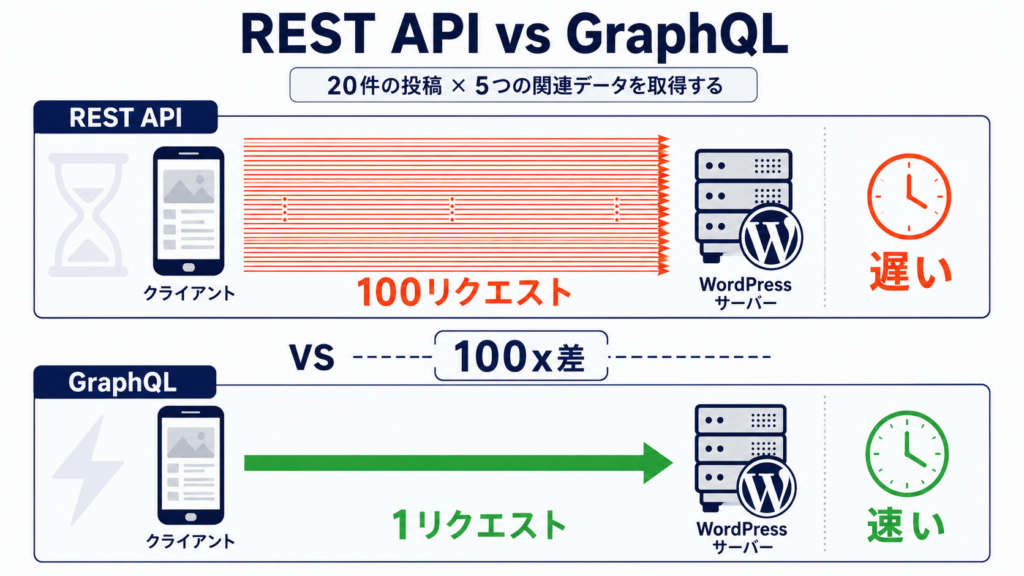
WordPress を「データソース」として扱うパターンは、年々増えています。フロントを React / Vue / Next.js で組み、WP は管理画面と API のみ、という構成です。
WordPress REST API の使い所と限界
- 標準で /wp-json/wp/v2/* が動く
- 認証は Cookie / Application Password / OAuth / JWT
- 拡張は register_rest_route で行う
- N+1 問題: 一覧取得後に各投稿のメタやタームを別 API で取りに行く構造
- フィールド選択は _fields パラメータで限定的に可能
<?php
/**
* カスタム REST エンドポイント例
* 一覧 + 必要メタを 1 リクエストで返す
*/
add_action( 'rest_api_init', function () {
register_rest_route( 'wn/v1', '/courses', [
'methods' => 'GET',
'permission_callback' => '__return_true',
'callback' => function ( $request ) {
$ids = get_posts( [
'post_type' => 'course',
'posts_per_page' => 20,
'fields' => 'ids',
'no_found_rows' => true,
'update_post_meta_cache' => true,
'update_post_term_cache' => true,
] );
$data = array_map( function ( $id ) {
return [
'id' => $id,
'title' => get_the_title( $id ),
'permalink' => get_permalink( $id ),
'price' => (int) get_post_meta( $id, 'price', true ),
'level' => get_post_meta( $id, 'level', true ),
'subjects' => wp_get_post_terms( $id, 'course_subject', [ 'fields' => 'names' ] ),
];
}, $ids );
return rest_ensure_response( $data );
},
] );
} );
WPGraphQL の利点と注意点
- クライアントが必要なフィールドだけ取得できる(オーバーフェッチ抑制)
- 1 リクエストで関連データをまとめて取得(N+1 を解消しやすい)
- 型システムで API 仕様が明示される
- ACF / WooCommerce / Yoast SEO の連携プラグインが揃っている
- クエリ複雑度のしきい値設定が必須(DoS 防止)
WPGraphQL を入れる前に考えること
- 永続化クエリ(Persisted Queries)の運用設計
- introspection を本番で無効化するか
- クエリ深さ制限と複雑度制限
- 認証戦略(Cookie / JWT / Application Password)
- object cache での結果キャッシュ戦略
認証戦略
| 方式 | 向くケース | 注意点 |
|---|---|---|
| Cookie + Nonce | 同一ドメインのフロント | クロスドメイン非対応 |
| Application Password | 外部ツール、CLI | ユーザー単位の発行と取り消しを運用化 |
| JWT | SPA、モバイル | リフレッシュトークン設計が必要 |
| OAuth | サードパーティ統合 | 実装コストが高い |
N+1 問題の解消パターン
<?php
// 悪い例: ループ内で個別にメタを取る(実行プランによっては
// object cache が効いて軽くなるが、本質的な無駄が残る)
foreach ( $course_ids as $id ) {
$price = get_post_meta( $id, 'price', true );
$level = get_post_meta( $id, 'level', true );
}
// 改善: メタを一括プリフェッチ
update_postmeta_cache( $course_ids );
foreach ( $course_ids as $id ) {
$price = get_post_meta( $id, 'price', true ); // キャッシュヒット
$level = get_post_meta( $id, 'level', true );
}
REST と GraphQL のどちらが優れているかではなく、「クライアント側がどう取りたいか」で決まります。フロントが React + Apollo なら GraphQL の親和性が高く、CLI や cURL ベースなら REST が素直です。
REST と GraphQL の選択は宗教論争になりがちですが、本質は「クライアントが何回 API を叩くか」で決まります。リスト表示で 20 件の投稿それぞれに 5 つの関連データが必要な場合、REST だと最大 100 リクエスト、GraphQL なら 1 リクエストで済みます。
とはいえ、GraphQL はサーバー側の複雑度が上がります。クエリ複雑度の制限、深さ制限、N+1 解消の DataLoader 的な仕組みが必要です。WPGraphQL は標準でこのあたりの土台を提供しますが、設定は明示的に行う必要があります。
<?php
// WPGraphQL: クエリ複雑度と深さの制限
add_filter( 'graphql_request_data', function ( $data ) {
// 本番では introspection を無効化
if ( ! is_admin() && ! current_user_can( 'manage_options' ) ) {
// 必要に応じて schema introspection を制限
}
return $data;
} );
add_filter( 'graphql_max_query_amount', function () {
return 50; // 1 回のクエリで取得できる最大件数
} );認証では Application Password が登場以降の現実解になりました。ユーザーごとに発行・取り消しでき、JWT 実装のような追加プラグインを必要としません。
SPA でログイン状態を維持する用途では JWT が向きますが、サーバー間連携では Application Password が素直です。
- Application Password はユーザーロールに連動する。最小権限のユーザーで発行する
- REST 経由でのデータ書き込みは、管理画面と同じ権限チェックを通る
- GraphQL は読み取り中心の設計が安全(書き込みは独自ミューテーションで明示)
- 外部公開する API は CORS / Origin チェックを明示的に書く
クライアント側のキャッシュ戦略も大事です。SWR、React Query、Apollo Cache などをどう設計するかで、サーバー負荷が桁違いに変わります。
サーバー側の object cache とクライアントキャッシュの両方を意識する必要があります。
「いつ WP の外に出るか」の判断基準

WordPress は万能ではありません。「乗せられる」が「乗せるべき」とは限らない、という観点をもう一段掘り下げます。
WP が苦手な領域
- リアルタイム性: チャット、ライブ更新。Pusher / Ably / 自前 WebSocket への分離が現実的
- 計算量大: 大量データの集計、機械学習推論。バックエンドを Python / Go に分離
- 大容量メディア: 動画配信は CloudFront / Mux / Vimeo に逃がす
- 高頻度書き込み: IoT、トラッキングログ。Kinesis / BigQuery / Timestream
- 全文検索: 高度な検索は Algolia / Meilisearch / ElasticPress
マイクロサービス分離の判断点
分離の判断は感情的になりがちです。次の 3 つの問いを通すと、判断が客観化します。
- Q1: この機能が止まった時、WP 本体は動き続けられるか
- Q2: この機能だけスケールさせたいケースがあるか
- Q3: 開発スピード / 言語 / 担当チームが WP と異なるか
3 つすべて Yes なら、分離の有力候補です。1 つでも No が含まれるなら、WP 内に保つコストの方が低いことが多いです。
外部サービス連携の典型
| 領域 | サービス | WP 側の役割 |
|---|---|---|
| 決済 | Stripe / Square / GMO | 顧客 ID と注文 ID の対応保持 |
| メール | SendGrid / Postmark / Mailgun | テンプレートと配信トリガ |
| 検索 | Algolia / Meilisearch | インデックス更新の hook |
| 分析 | GA4 / Mixpanel / Clarity | 計測 ID の埋め込みと PII 除去 |
| メディア | Cloudinary / Mux / Imgix | URL の書き換え |
DB を切り離す勇気
WordPress の DB と、ビジネスの DB は別物だと割り切る判断は、ある規模を超えた時に有効です。
- ユーザー DB は Auth0 / Cognito に出す
- 注文 DB は自前 PostgreSQL に出す
- WP は「フロントの表示器」として薄く保つ
外に出す前のチェック
- 外に出した DB から WP に戻す経路が用意できているか
- 外側の停止が WP 全体停止を意味しないか(degraded mode)
- 障害切り分けの一次窓口がはっきりしているか
- セキュリティ境界が明確か(trust boundary)
ヘッドレス WP に移る基準
第4回 でも触れましたが、ヘッドレス化は技術的な憧れではなく、ビジネスの要件で決まります。
- フロントの体験が WP テーマで表現しきれない(モバイルアプリと並走するなど)
- 編集者と読者の体験を完全に分けたい
- WP 単体での CDN / キャッシュ最適化が限界
- 複数フロント(Web / アプリ / Kiosk)を同一 CMS で運用したい
逆に「速くしたい」だけならヘッドレス化は過剰投資です。フルページキャッシュとオブジェクトキャッシュで多くの場合は解決します。
「外に出す」は逃げではなく設計判断です。WordPress の良さは「最初の 80% を素早く形にできる」ことで、外に出すべきものは最初から外、と決める胆力が後の運用コストを左右します。
「外に出す」判断の最大の壁は、現場の心理的負担です。WordPress 内で完結するほうがオペレーション的に楽に見えるからです。しかし、これは短期視点の判断であって、5 年後の運用負荷を考えると逆転することが多くなります。
具体的な判断材料として、SLO(Service Level Objective)を導入すると客観化しやすいです。「このページは 200ms 以内に表示する」「決済 API は 99.9% 稼働させる」といった目標を立て、WP に乗せたままで達成可能かを評価します。
- 目標応答時間が 100ms 未満:WP のフルページキャッシュ前提でも厳しい。CDN + 静的化 / ヘッドレス検討
- 目標可用性 99.99%:単一 WP サーバーでは困難。冗長化と外部サービス分離が前提
- 目標同時接続数 1,000+:書き込みは外部サービスに分離、WP は読み取り中心
- 編集 UI と公開 UI が大幅に異なる:ヘッドレス検討
外出しの順序(推奨)
- Step 1: メール送信を SaaS に出す(運用負荷が高く効果が見えやすい)
- Step 2: 検索を外に出す(パフォーマンス改善が大きい)
- Step 3: メディア配信を CDN / Cloudinary に出す
- Step 4: 決済を外部に出す(多くの場合最初から外)
- Step 5: ユーザー認証を外に出す(最も難易度が高い)
段階的な外出しを進めていくと、最終的に「WP は管理画面 + テンプレートのみ」という薄い状態に近づきます。ここまで来ると、ヘッドレス化はもう半分終わっている とも言えます。
まとめ — 「Web アプリ」として WP を扱う 7 つの設計原則
ここまで 11 のテーマにわたり、WordPress を Web アプリの実行基盤として扱う際の判断軸を見てきました。最後に 7 つの原則として圧縮します。
- 原則 1: post に「乗せられる」と「乗せるべき」を区別する
- 原則 2: CPT は最小の supports と独自 capability_type から始める
- 原則 3: Taxonomy か Meta かは「URL を持たせたいか」で分ける
- 原則 4: meta_query の AND が常時 3 を超えたら Custom Table を検討する
- 原則 5: ロールは足し算ではなく割り算で設計する
- 原則 6: 「クエリで取らない、スナップショットで取る」をキャッシュ戦略の起点にする
- 原則 7: 外に出す勇気を最初に確保する。WP を中心に置きすぎない
チェックリスト
設計レビュー時のチェック
- CPT の show_in_rest が意図と一致しているか
- capability_type を ‘post’ のまま放置していないか
- meta_query の AND が日常的に 3 を超える設計になっていないか
- 10,000 件超で動くことを想定したテストデータがあるか
- ロールの capability 一覧を文書化しているか
- クエリ結果のキャッシュ無効化が hook で網羅されているか
- 外部サービスとの reconciliation バッチが用意されているか
第8回への伏線
今回は「データモデルの設計」を扱いました。次の 第8回 では、これらの設計を壊さずに運用し続けるための仕組みを扱います。Git ベースの変更管理、CI/CD、マイグレーションの自動化、ステージング戦略。
「設計したものを 5 年運用する」テーマです。
CPT を作るのは 1 日、運用は 5 年。設計の重さは「最初の register_post_type に何を書き込んだか」ではなく、「3 年後、誰が見ても理解できるか」で測られます。
WordPress を Web アプリとして扱うとは、つまり「便利すぎるデフォルトを意識的に殺し、設計判断を可視化する」作業の連続です。
第7回を通して伝えたかったのは、WordPress を「便利な箱」ではなく「設計の対象」として扱う視点です。
register_post_type の引数 1 つ、capability_type の指定 1 つ、meta か Custom Table かの選択 1 つが、3 年後の運用工数を桁単位で動かします。
逆に言えば、これらの設計判断を意識的に行えば、WordPress は十分に Web アプリの基盤として機能します。CMS としての柔軟さと、Web アプリとしての堅牢さを両立させる鍵は、デフォルト値を疑い、判断を文書化する習慣にあります。
読者の皆さんが現場で次にカスタム投稿型を追加する時、この章の 7 つの原則を 1 つでも思い出していただけたら、それで十分です。
第8回は「運用設計」がテーマです。設計したものを壊さず維持する仕組み、ステージングと本番のドリフトを止める仕組み、を整理します。今日の話とセットで、運用 5 年を見据えた WP 構築の土台が揃います。
7 つの原則は、フィールドで蓄積した「失敗パターンの裏返し」です。原則 1 を破ると「post に乗せすぎてクエリが重い」、原則 4 を破ると「meta が肥大化して何もかも遅い」、原則 7 を破ると「WP に乗せすぎて分離できなくなる」といった具体的な後悔につながります。
これらは個別の Tips ではなく、設計判断のフレームとして使えるはずです。新しい CPT を作る前、新しい機能を追加する前、新しいプラグインを入れる前に、7 つの原則を 1 つずつチェックする 5 分が、5 年の運用負債を防ぎます。
そして、原則 7「外に出す勇気を最初に確保する」 は、最初の設計時点では実行しない選択でもよいのです。重要なのは「外に出せる構造で書く」こと。サービス間の依存を hook と関数で疎結合に保ち、後から差し替え可能な状態を維持します。
- 結合度の低い hook ベースの実装を選ぶ
- 外部サービスは抽象化レイヤーを通す(直接 API を呼ばない)
- DB アクセスは関数経由(直接 SQL を散らさない)
- 認証情報は wp-config.php や環境変数に置く(DB に置かない)
WordPress を Web アプリとして扱う設計判断は、結局のところ「明日も明後日も、別の誰かが触れる状態にしておく」ことに帰着します。第8回では、この設計を維持する仕組み(Git、CI/CD、ステージング、マイグレーション)を扱います。





